 Авто
Авто







Рейтинг основных форумов
Городские форумы
Городской форум
Городской форум для новичков
Нижегородская политика
Жалобная книга
Бабский форум
Мужской
Анонимный медицинский форум
Дурацкие вопросы
Автофорумы
Автофорум главный
Девушка за рулем
ВАЗ форум
4х4 форум
Жалобный
Шевроле Форум
Такси
Автозапчасти
Гаражный форум
KIA-форум
Рено форум
Hyundai Форум
VAG Форум
Форумы покупок
Центр раздач: информационный форум
Глав-Пристрой (со всех форумов, взрослый)
Совместная покупка
Совместная покупка: центральный
Совместная покупка: взрослый
Совместная покупка: вкусный
Совместная покупка: мама и малыш
Совместная покупка: уютный
Совместная покупка: сбор предоплаты, раздачи
Совместная покупка: услуги
Совместная покупка: область
Совместная покупка: Дзержинск
Совместная покупка: Саров
Зарубежные интернет-покупки
Покупаем вместе
Покупаем Вместе: Основной
Покупаем вместе: БОЛЬШОЙ ШОПИНГ (взрослый)
Покупаем вместе: БЕБИ-ШОП (детский)
Покупаем вместе: ДОМОВОЙ
Покупаем вместе: ГАСТРОНОМ
Покупаем вместе: Сбор предоплаты, раздачи
Покупаем Вместе: пристрой
Покупаем Вместе: услуги
Выгодная покупка
Выгодная покупка - общие вопросы
Выгодная покупка - взрослый
Выгодная покупка - детский
Выгодная покупка - сбор предоплаты, раздачи
Выгодная покупка - объявления
Форум закупок
Мой малыш
Мой малыш - Основной
Мой малыш - Объявления. Общий
Мой малыш - Объявления: детская одежда
Мой малыш - Объявления: детская обувь
Мой малыш - Объявления: детский транспорт, игрушки, мебель
Халявный
Халявный (основной)
Котята и др. животные
Элитный (продажа неликвидных товаров)
Услуги
Домоводство
Полезный форум
Бытовые проблемы
Деревенский форум
Домоводство
Цветочный форум
Форум владельцев кошек
Дачный. Основной.
Бытовая Техника
Творческий
Рукоделие основной
Форумы по интересам
Фиолетовый форум
Сделаны в СССР
Музыкальный
Кино форум
Кладоискатели и коллекционеры
Рыболовный
Охотничий
Стильный форум
Флирт, Любовь, Знакомства
Фотофорум
Здоровье
Развитие Человека
Пивной форум
Кулинарный
Парфюмерный
Парфюмерная Лавка
Собачий форум
Собачий форум: Основной
Собачий форум: пристрой животных
Наши Дети
Наши дети
Школьный форум
Особые дети
Технофорумы
Интернет-НН
GPS форум
Мобильный форум
Техно-форум
Технотуса
Проф. и бизнес форумы
Бизнес форум
Фотография
Недвижимость
Банковский форум
Медицина
Форум трейдеров
Бухучет и аудит
Юридический
Подбор персонала
Разработчики ПО
Строительные форумы
Строительный форум (основной)
Окна
Форум электриков
Мебель
Кондиционирования и вентиляция
Форум строительных объявлений
Форум проектировщиков
Все строительные форумы
Туризм, отдых, экстрим
Туризм, отдых, экстрим
Спортивные форумы
Клуб болельщиков
Спортплощадка
Боевые искусства
Велофорумы Нижнего Новгорода
Велофорум Нижнего Новгорода
Путешествия
Нижегородская область
Недвижимость
Недвижимость
Ипотека
Земельный форум
ТСЖ
Садоводческое товарищество
Жилые районы
Автозаводский район
Сормовский район
Мещерское озеро
Все форумы районов
Форумы домов
Корабли
Новая Кузнечиха
Октава ЖК (ул. Глеба Успенского)
Мончегория ЖК
Аквамарин ЖК (Комсомольская пл.)
Сормовская Сторона ЖК
КМ Анкудиновский парк ЖК
Красная Поляна ЖК (Казанское шоссе)
Времена Года ЖК (Кстовский р-он)
Стрижи ЖК (Богородский р-он)
На Победной ЖК (Победная ул., у дома 18)
Окский берег ЖК (п. Новинки)
Цветы ЖК (ул. Академика Сахарова)
Деревня Крутая кп (Кстовский р-он)
Опалиха кп (Кстовский р-он)
Юг мкр. (Южный бульвар)
Гагаринские высоты мкр.
Бурнаковский мкр.
Белый город мкр. (60-лет Октября ул.)
Зенит ЖК (Гагарина пр.)
Седьмое небо ЖК
Все форумы домов
Частные форумы
Свадебный форум
Саровский Клуб Покупателей
Июньские мамочки
Форум безумных идей
Ночной форум
Королевство кривых зеркал
Ищу вторую половинку!
Лютики-цветочки КУПЛЯ-ПРОДАЖА
Отряд стройности
Пчеловодство
Форум ленивых
Волейбольный клуб туристов
Встречи для секса
Буду мамой!
Алкогольный форум
Лютики-цветочки
Котоводство
Форум сексуального опыта
Свободка
Форум модераторов
Форум забаненных
Новый форум модераторов
Отзывы и предложения (техподдержка)
Почему SIFT дескрипторы scale invariant (да и к rotate тоже invariant) ?
Серьёзная тема
369
15
Поделиться

Я честно гуглил, в т.ч. читал и про пирамиду изображений (scale) и что 8x8 части картинки выравниваются по доминантному градиенту (rotate)...
Не понятно пока вот что:
если мы идём по большой картинке, в которой собсно и ищем,
паттерном 2x2,
который в свою очередь состоит из 4-х кусочков 8x8 пикселей (в итоге размер окна 16x16),
в каждом из которых посчитаны градиенты (гистограмма) по 8-ми направлениям
(получается feature vector из 32 целочисленных элементов),
то что если фича ("подкартинка" 16x16) в большой картинке НЕ выравнена ровно на 8 пикселей? это же часто возникающая ситуация будет. как он тогда находит? ведь градиенты уже будут другие...
Не понятно пока вот что:
если мы идём по большой картинке, в которой собсно и ищем,
паттерном 2x2,
который в свою очередь состоит из 4-х кусочков 8x8 пикселей (в итоге размер окна 16x16),
в каждом из которых посчитаны градиенты (гистограмма) по 8-ми направлениям
(получается feature vector из 32 целочисленных элементов),
то что если фича ("подкартинка" 16x16) в большой картинке НЕ выравнена ровно на 8 пикселей? это же часто возникающая ситуация будет. как он тогда находит? ведь градиенты уже будут другие...
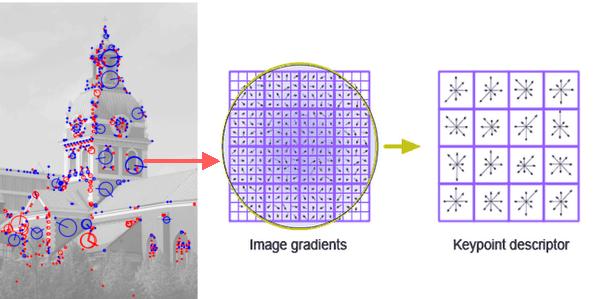
А что, собственно смущает? Там же поиск идет не каждого дескриптора по отдельности, а сразу всех. Ищется некоторое преобразование (например, матрица гомографии) и смотрится хорошо дескрипторы совпадают или не очень.
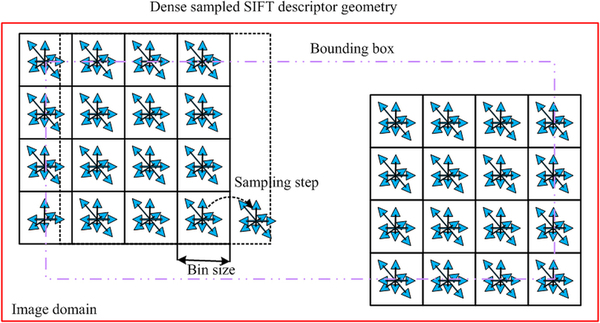
там же окно 16x16 смещается не на каждый пиксель за шаг (а то дофига вычислений), а сразу на 8 (на один bin), см. картинку.
а искомое изображение может быть смещено не ровно по границе с шагом 8 (как обучали), а ещё на 2-3-4 пикселя, например.
ну допустим (упростим) мы ищем маленькое 16x16 изображение (фича = искомое изображение), состоящее из 4-х bin'ов 8x8
если оно в большой картинке по границе 8x8 выровнено (и по X и по Y) - всё замечательно, будет 100% совпадение с искомым, т.к. евклидово расстояние в 32-мерном пространстве будет = 0
но если искомое изображение будет смещено, т.е. не по 8x8 выровнено, то будет ли евклидово расстояние в 32-мерном пространстве (4 бина, каждый - усреднённая гистограмма векторов в 8 направлениях) тоже относительно малО ?
p.s. ещё интересно вот что: как искомые картинки, так и сами изображения на которых их искать будем - они не кратны 8 пикселям по ширине и высоте, т.е. получается их как-то надо немного "подгонять" перед обработкой? ну например, делить на цело на 8 и по X и по Y, а потом полученное число умножать на 8, а остаток отбрасывать - по идее пропорции (визуально) не страдают при этом...
а искомое изображение может быть смещено не ровно по границе с шагом 8 (как обучали), а ещё на 2-3-4 пикселя, например.
ну допустим (упростим) мы ищем маленькое 16x16 изображение (фича = искомое изображение), состоящее из 4-х bin'ов 8x8
если оно в большой картинке по границе 8x8 выровнено (и по X и по Y) - всё замечательно, будет 100% совпадение с искомым, т.к. евклидово расстояние в 32-мерном пространстве будет = 0
но если искомое изображение будет смещено, т.е. не по 8x8 выровнено, то будет ли евклидово расстояние в 32-мерном пространстве (4 бина, каждый - усреднённая гистограмма векторов в 8 направлениях) тоже относительно малО ?
p.s. ещё интересно вот что: как искомые картинки, так и сами изображения на которых их искать будем - они не кратны 8 пикселям по ширине и высоте, т.е. получается их как-то надо немного "подгонять" перед обработкой? ну например, делить на цело на 8 и по X и по Y, а потом полученное число умножать на 8, а остаток отбрасывать - по идее пропорции (визуально) не страдают при этом...
Ivanushka-durachok писал(а)
а сразу всех
а сразу всех
это при SVM, когда нам важен "факт наличия"
а если ищем конкретику? (см. далее)
я правильно понимаю вот что:
1) допустим, что обучаем N маленьким картинкам
2) допустим одна картинка 64x64
3) т.е. из неё полноразмерной (дескриптор это 16x16, состоит из 4-х bin'ов 8x8) получится 7x7=49 дескрипторов (шаг по 8 пикселей же)
3а) ну и если пирамиду изображений делаем, то из неё же получим картинки 56x56 (6x6=36 дескрипторов), 48x48 (5x5=25 дескрипторов), 40x40, 32x32, и т.д., а из них в свою очередь тоже получатся дескрипторы
4) допустим не используем SVM для разделения дескрипторов с positive и negative картинок, а используем именно евклидово расстояние (с неким порогом дальности, 0 - идеальное совпадение) каждой фичи на картинке с каждой фичей в БД (т.е. не "ищем на картинке машину", а "ищем на картинке BMW x6 и ничего другого")
но это ж тогда просто ахринеть:
- на картинке в которой ищем допустим 1920x1080 будет 240x135=32400 (с шагом по 8 точек то) дескрипторов для сравнения;
- допустим у нас 100 картинок 64x64, т.е. каждая это 49 дескрипторов = 4900 дескрипторов в БД для сравнения;
- итого надо для поиска в одной картинке посчитать 32400x4900=158'760'000 евклидовых расстояний (между дескрипторами, т.е. в 32-мерном пространстве) и сравнить threshold;
- и это только для 64x64, без пирамиды изображений (т.е. без вариантов, что искомая картинка меньше/дальше на фото);
опять же, это без SVM, т.е. мы ищем не "лицо человека на картинке" (SVM - лицо или нет), а "Васю или Петю, причём с указанием кто это был найден" (евклидово расстояние между сравниваемым дескрипторами с неким threshold'ом)
Что-то у вас все в кучу. Вы как картинки сравнивать собрались? Если по характерным точкам, то их немного, как правило. Тогда получается не 158'760'000 сравнений, а гораздо меньше. А если просто картинки сопоставляете по их дескрипторам, тогда да, ахринеть :) Не зря же подобные алгоритмы на GPU считают. Плюс во втором варианте вам инвариантность SIFT к повороту уже не поможет, придется исходную картинку самому крутить, поскольку при представлении набора SIFT дескрипторов в виде вектора у вас теряется пространственная информация. Тут можно сравнивать картинки либо частями, либо использовать всякие хитрые штуки типа transportation distance и иже с ними.
Что касается вопроса про некратность размера картинки 8 пикселям... ну можно ее подрезать, либо дополнять. Посмотрите, как сделано в матлабовских реализациях SIFT, ну или в OpenCV.
Что касается вопроса про некратность размера картинки 8 пикселям... ну можно ее подрезать, либо дополнять. Посмотрите, как сделано в матлабовских реализациях SIFT, ну или в OpenCV.
в свое время, я успешно решил задачу поиска одинаковых\похожих картинок на такой приличной выборке (от 100 тыс картинок), картинки поврежденные всякими шумами, углами поворота, масштабом, аморфные итд итп.
Александр, привет! далее будет объяснение твоего вопроса о кратности пикселя 8, по сути вопрос не корректен, он должен отпасть сам собой.
1. характерных точек (тут речь идет о особых точках, после sift преобразования) - их количество смотря какой порог задашь, столько и будет этих точек определено.
2. многие ошибочно полагают, что особые точки (в том числе в SIFT преобразовании) - это точки, но на самом деле это области и дескриптор описывает ОБЛАСТЬ. Точка - это центр области.
4. дескриптор - характеризует степень изменения градиента по всем направлениям (грубо, по фиксированным углам), чем больше их число, тем больше стойкость к повороту. Реально получается, что при сравнении на некоторые углы, результат будет хуже\лучше чем на другие углы. Вручную крутить картинку на разные углы - улучшений при сравнении не даст. Инвариантность к повороту достигается за счет того что описаны основные углы... и как бы это выразиться, степень\резкость изменения картинки в основном попадает на описываемые углы.
5. как выбирается центр области, те сама точка? по сути, при поиске сравнивается как сильно деформируется область около токи при смене масштаба. Если описание области примерно стабильно для какого то диапазона масштаба (те как пример - это одноцветная область или область с плавно меняющимся градиентом), то данная область будет ключевой точкой, те будет найден ее центр. Выбираются наиболее удачные точки по порогу, и описывается их области, те от сюда следует, что вообще пофик как выравнены точки на картинках.
6. Сравнение картинок в разных масштабах работает "до поры до времени", по сути, зависит от порога, по которому мы выбирали особые точки. Чем больше порог - тем меньше точек будут стабильных к масштабу (те описываться будут монотонные большие области). А да, как правило, если масштаб отличается в 2 раза, то дескрипторы резко перестают сходиться, так что сифт\серф преобразования не так уж и инварианты к масштабу ;)
7. на самом деле, при сравнении дескприторов, не так уж и много ключевых точек совпадет (хотя зависит от экспериментального порога), но это не значит что чем больше ключевых точек тем лучше... Для большого кол-ва точек начнут возникать коллизии в их описании (те реально будут сопоставляться те точки что не должны, это кстати можно видеть на многочисленных видео про сифт\серф преобразования).
8. конечно-же делать дескриптор для в точке или каждые 8х8 - это бред, их слишком много, описание нужно делать только хорошей области.
9. "а сразу всех" - это я вообще не понял о чем речь. Реально дескприпторы двух картинок сравниваются полным перебором (те если на одной картинке 1000 ключевых точек, и на другой 1000 тогда будет 1000*1000 итераций), высчитывается евклидово расстояние и сравнивается с порогом... прошла по порогу? области считаются одинаковыми. Полагаю, автор имел ввиду следующее. Как то называется такая штука, что можно определять аморфную матрицу по УЖЕ СОПОСТАВЛЕННЫМ ключевым точкам. Вот на этом этапе, как то хитро\оптимизированно идут просчеты.
интересно, если не секрет для чего поднялась тема сифт\серф преобразований. Это поиск\сравнение картинок (или части картинок) или это для видео, как изменились объекты по кадрам?
Александр, привет! далее будет объяснение твоего вопроса о кратности пикселя 8, по сути вопрос не корректен, он должен отпасть сам собой.
1. характерных точек (тут речь идет о особых точках, после sift преобразования) - их количество смотря какой порог задашь, столько и будет этих точек определено.
2. многие ошибочно полагают, что особые точки (в том числе в SIFT преобразовании) - это точки, но на самом деле это области и дескриптор описывает ОБЛАСТЬ. Точка - это центр области.
4. дескриптор - характеризует степень изменения градиента по всем направлениям (грубо, по фиксированным углам), чем больше их число, тем больше стойкость к повороту. Реально получается, что при сравнении на некоторые углы, результат будет хуже\лучше чем на другие углы. Вручную крутить картинку на разные углы - улучшений при сравнении не даст. Инвариантность к повороту достигается за счет того что описаны основные углы... и как бы это выразиться, степень\резкость изменения картинки в основном попадает на описываемые углы.
5. как выбирается центр области, те сама точка? по сути, при поиске сравнивается как сильно деформируется область около токи при смене масштаба. Если описание области примерно стабильно для какого то диапазона масштаба (те как пример - это одноцветная область или область с плавно меняющимся градиентом), то данная область будет ключевой точкой, те будет найден ее центр. Выбираются наиболее удачные точки по порогу, и описывается их области, те от сюда следует, что вообще пофик как выравнены точки на картинках.
6. Сравнение картинок в разных масштабах работает "до поры до времени", по сути, зависит от порога, по которому мы выбирали особые точки. Чем больше порог - тем меньше точек будут стабильных к масштабу (те описываться будут монотонные большие области). А да, как правило, если масштаб отличается в 2 раза, то дескрипторы резко перестают сходиться, так что сифт\серф преобразования не так уж и инварианты к масштабу ;)
7. на самом деле, при сравнении дескприторов, не так уж и много ключевых точек совпадет (хотя зависит от экспериментального порога), но это не значит что чем больше ключевых точек тем лучше... Для большого кол-ва точек начнут возникать коллизии в их описании (те реально будут сопоставляться те точки что не должны, это кстати можно видеть на многочисленных видео про сифт\серф преобразования).
8. конечно-же делать дескриптор для в точке или каждые 8х8 - это бред, их слишком много, описание нужно делать только хорошей области.
9. "а сразу всех" - это я вообще не понял о чем речь. Реально дескприпторы двух картинок сравниваются полным перебором (те если на одной картинке 1000 ключевых точек, и на другой 1000 тогда будет 1000*1000 итераций), высчитывается евклидово расстояние и сравнивается с порогом... прошла по порогу? области считаются одинаковыми. Полагаю, автор имел ввиду следующее. Как то называется такая штука, что можно определять аморфную матрицу по УЖЕ СОПОСТАВЛЕННЫМ ключевым точкам. Вот на этом этапе, как то хитро\оптимизированно идут просчеты.
интересно, если не секрет для чего поднялась тема сифт\серф преобразований. Это поиск\сравнение картинок (или части картинок) или это для видео, как изменились объекты по кадрам?
nop писал(а)
4. дескриптор - характеризует степень изменения градиента по всем направлениям (грубо, по фиксированным углам), чем больше их число, тем больше стойкость к повороту.
4. дескриптор - характеризует степень изменения градиента по всем направлениям (грубо, по фиксированным углам), чем больше их число, тем больше стойкость к повороту.
при повёрнутости одного элемента картинки по отношению к другому - у одинаковых, но повёрнутых относительно друг друга элементов картинок значения градиентов будут как бы shift'нуты в массиве (отдельный дескриптор - это же по сути массив), разве нет?
т.е. всё равно при прямом сравнении они не совпадут ведь...
ну, например, обучили фиче где наибольший градиент в массиве был на 90 градусов (вверх), а встретили 1:1 эту же фичу, но повёрнутую ещё на +45 градусов, у неё наибольший градиент будет уже на 90+45=135 градусов, т.е. на другой позиции в массиве.
nop писал(а)
сравнивается как сильно деформируется область около токи при смене масштаба
сравнивается как сильно деформируется область около токи при смене масштаба
не совсем понял, что значит "деформируется"
ок, если взять не SIFT с его пирамидой изображений и размытием по Гауссу, а обычный самый простейший HOG (Гистограмма ориентированных градиентов), то не понятно как там тогда находятся похожие (того же масштаба, с тем же углом поворота), ведь если в изображении в котором ищём ("большая картинка") искомое изображение ("маленькая картинка") не выравнено на 8, то мы получим совсем другие уже градиенты...
p.s. тема поднялась, скажем так, для академического интереса :)
> т.е. на другой позиции в массиве.
я понял о чем ты спрашиваешь, ты хочешь сказать, что элемент из массива дескрипторов на позиции N характеризует строго какой то угол. Это не так. Предположим, выбирается из всех градиентов наибольший (или наименьший, не принципиально), считается, что угол соответствующих этому элементу будет стартовым, те в массиве дескрипторов он пусть будет на 0-м месте, дальше по кругу (в любую сторону) от этого угла последовательно записываются дескрипторы в элементы массива. Это приведет к тому что будет пофик как повернута картинка, набор дескрипторов будет в одних и тех же номерах массива.
я не понимаю почему ты говоришь про выравнивание 8 всего изображения, оно не играет ни какой роли. Выделилась ключевая точка описывается область около нее.... причем тут эффект выравнивания, который вообще фигурировать может на границах всей картинки? Давай на примере, представь бинарную картинку, черный не залитый круг на белом фоне, где будет находить первая ключевая точка? ровно по центру круга (кстати, значение градиента во все стороны будет одинаковым), те ключевая точка описывает область\внутренность круга. Представь такой же круг но другого масштаба, где будет ключевая точка? также в центре, с таким же набором дескрипторов. Те евклидово расстояние между дескрипторами 0, ну все, ты говоришь что точки сошлись..... а масштаб в этом примере вообще не играет роли. Аналогично для других сложных областей с любыми перепадами градиента, да в них влияние масштаба будет более значительней, и после какого то предела начнутся обломы, по этому я и говорил, что ставятся пороги на определение ключевых точек так, чтобы выделить наиболее удачные, которые стабильны к масштабу. В общем случае, размер картинки в сифт\сюрф ВЛИЯЕТ на сравнение, его влияние не значительно лишь в каких то пределах.
В интернете есть сравнение разных алгоритмов выявления ключевых точек, и там есть сравнительные графики, как масштаб\поворот влияет на выявление ключевых точек, в зависимости от алгоритма и дескрипторов. Какие то алгоритмы более стабильны к повороту (дают не 100% а чуть лучше результат), какие то на масштаб... итд. Ни один из алгоритмов не дает 100% инвариантности к масштабу.
я понял о чем ты спрашиваешь, ты хочешь сказать, что элемент из массива дескрипторов на позиции N характеризует строго какой то угол. Это не так. Предположим, выбирается из всех градиентов наибольший (или наименьший, не принципиально), считается, что угол соответствующих этому элементу будет стартовым, те в массиве дескрипторов он пусть будет на 0-м месте, дальше по кругу (в любую сторону) от этого угла последовательно записываются дескрипторы в элементы массива. Это приведет к тому что будет пофик как повернута картинка, набор дескрипторов будет в одних и тех же номерах массива.
я не понимаю почему ты говоришь про выравнивание 8 всего изображения, оно не играет ни какой роли. Выделилась ключевая точка описывается область около нее.... причем тут эффект выравнивания, который вообще фигурировать может на границах всей картинки? Давай на примере, представь бинарную картинку, черный не залитый круг на белом фоне, где будет находить первая ключевая точка? ровно по центру круга (кстати, значение градиента во все стороны будет одинаковым), те ключевая точка описывает область\внутренность круга. Представь такой же круг но другого масштаба, где будет ключевая точка? также в центре, с таким же набором дескрипторов. Те евклидово расстояние между дескрипторами 0, ну все, ты говоришь что точки сошлись..... а масштаб в этом примере вообще не играет роли. Аналогично для других сложных областей с любыми перепадами градиента, да в них влияние масштаба будет более значительней, и после какого то предела начнутся обломы, по этому я и говорил, что ставятся пороги на определение ключевых точек так, чтобы выделить наиболее удачные, которые стабильны к масштабу. В общем случае, размер картинки в сифт\сюрф ВЛИЯЕТ на сравнение, его влияние не значительно лишь в каких то пределах.
В интернете есть сравнение разных алгоритмов выявления ключевых точек, и там есть сравнительные графики, как масштаб\поворот влияет на выявление ключевых точек, в зависимости от алгоритма и дескрипторов. Какие то алгоритмы более стабильны к повороту (дают не 100% а чуть лучше результат), какие то на масштаб... итд. Ни один из алгоритмов не дает 100% инвариантности к масштабу.
nop писал(а)
Предположим, выбирается из всех градиентов наибольший (или наименьший, не принципиально), считается, что угол соответствующих этому элементу будет стартовым, те в массиве дескрипторов он пусть будет на 0-м месте
Предположим, выбирается из всех градиентов наибольший (или наименьший, не принципиально), считается, что угол соответствующих этому элементу будет стартовым, те в массиве дескрипторов он пусть будет на 0-м месте
ага, понял.
я так и предполагал (выделяется наибольшее значение градиента), но не думал, что это на этапе построения дескрипторов так делать надо, думал, что при поиске их надо shift'ить :)
nop писал(а)
я не понимаю почему ты говоришь про выравнивание 8 всего изображения, оно не играет ни какой роли.
я не понимаю почему ты говоришь про выравнивание 8 всего изображения, оно не играет ни какой роли.
не всего, а см. 2-ю картинку в этой теме.
там окно 4x4 bin'a, каждый 8x8 пикселей.
и это окно бежит по картинке с шагом в 1 bin (8 пикселей).
а искомая картинка (фича, которую ищем) внутри большой картинки (на которой ищем) может лежать НЕ выровненной на 8 пикселей и соответственно у неё будут другие градиенты в пределах одного bin'a
ещё проще:
допустим глаз укладывается в 1 bin (8x8) и мы посчитали для него градиенты и "выучили", что такой дескриптор это - глаз.
допустим мы бежим (фиг с ним с масштабом) по большой картинке окном 8x8 (один bin).
а в большой картинке глаз оказался между двумя bin'ами, и когда мы их последовательно сравним с дескриптором глаза, то не найдём его, т.к. на одном будет полглаза и на другом, а у них градиенты будут другие.
вот даже нарисовал :)) ------------------------->
p.s.
ок, тогда как работает не SIFT, а простой банальный HOG ?
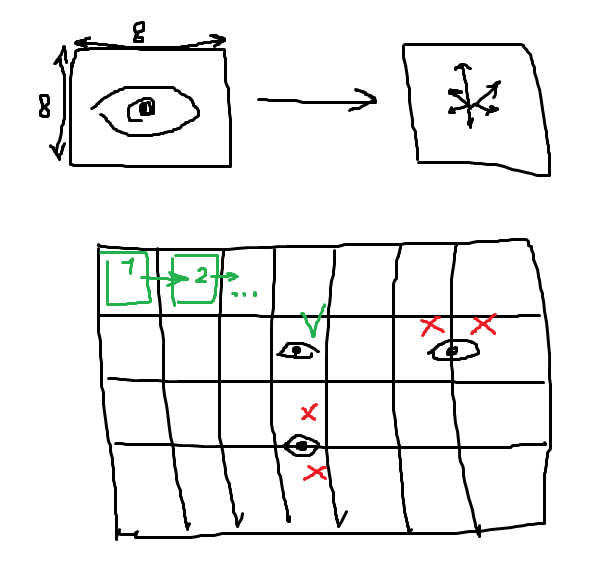
Александр, чем больше я пытаюсь понять про что ты говоришь, тем меньше понимаю. Ничего там не двигается, ни что не бежит... есть ключевая точка, она описывается, все.
https://ru.wikipedia.org/wik...1%82%D0%BE%D0%B2
говорят что оч похожи ;) тут говорят что есть отличия
https://www.quora.com/Comput...ature-descriptor
https://www.quora.com/Comput...nse-SIFT-and-HOG
правда где то по середине:)
https://ru.wikipedia.org/wik...1%82%D0%BE%D0%B2
говорят что оч похожи ;) тут говорят что есть отличия
https://www.quora.com/Comput...ature-descriptor
https://www.quora.com/Comput...nse-SIFT-and-HOG
правда где то по середине:)
nop писал(а)
Ничего там не двигается, ни что не бежит...
Ничего там не двигается, ни что не бежит...
по первой твоей же ссылке есть словосочетание "sliding window" которое кагбэ намекает, что таки бежит... :)
stackoverflow.com/questions/5596284/histogram-of-oriented-gradients - и таки бежит, причём с overlap'ом
ну и вот пруф на видео: https://youtu.be/SPXocFBjr70
но тут SVM, т.е. детектит только "машина" / "НЕ машина", а не конкретную машину (или хотя бы марку)
и не понятно мне вот что: если бежит с неким шагом (не каждый пиксель), то получается, что даже при смещении градиенты всё же достаточно совпадают?
Вы не путайте детектирование объектов с их сравнением. В приведенном выше случае не используются ключевые точки для сравнения и дескриптор может быть любым (SIFT, SURF, HOG, LBP и т.д.). Сравнение производится сразу на нескольких масштабах. Т.е. строим пирамиду на основе анализируемого изображения. После этого начинаем двигать окно фиксированного размера на каждом уровне пирамиды. В этом окне вычисляются признаки (плотные обычно) и итоговый вектор подается на классификатор. Если классификатор сработал на каком-то из масштабов, то масштабируем результирующий прямоугольник к размеру исходного изображения и запоминаем результат. Так поступаем для всех уровней пирамиды и на выходе получаем набор прямоугольников с обнаруженными объектами. Там можно делать еще дополнительный refining, но это уже детали.
Вообще вам нужно почитать какую-нибудь хорошую книжку по компьютерному зрению, чтобы лучше понимать какие обычно в данной области возникают задачи и как они решаются.
Вообще вам нужно почитать какую-нибудь хорошую книжку по компьютерному зрению, чтобы лучше понимать какие обычно в данной области возникают задачи и как они решаются.
я литературу читал.
HOG самый простой для понимания.
и он не просто для детектирования, можно (есть примеры) распознавать позу человека (стоит, идёт, бежит, присел и т.д.), например.
у меня вполне конкретный вопрос, даже картинку нарисовал -------------------->
что если искомое изображение смещено с шагом, отличным от одного bin'a (8 пикселей) ?
гистограмма градиентов в 8-ми направлениях будет уже другой и объект не найдётся по идее...
по идее конечно можно sliding window двигать на 1 пиксель, но возрастает количество вычислений.
HOG самый простой для понимания.
и он не просто для детектирования, можно (есть примеры) распознавать позу человека (стоит, идёт, бежит, присел и т.д.), например.
у меня вполне конкретный вопрос, даже картинку нарисовал -------------------->
что если искомое изображение смещено с шагом, отличным от одного bin'a (8 пикселей) ?
гистограмма градиентов в 8-ми направлениях будет уже другой и объект не найдётся по идее...
по идее конечно можно sliding window двигать на 1 пиксель, но возрастает количество вычислений.
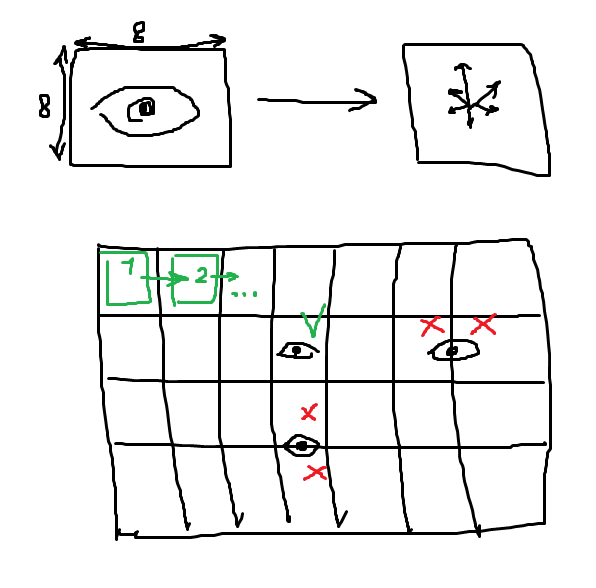
Почему обязательно гистограмма градиентов будет другой. Может быть и той же самой. Все зависит от размеров объекта и размеров окна, на котором вычисляются признаки, обобщающей способности классификатора. И никто не заставляет сдвигать окно поиска сразу на 8 пикселей, можно и меньше сдвиг делать. Обычно выбирают некий компромисс между скоростью работы и качеством/точностью обнаружения.
Что касается вашей картинки, то с чего вы взяли, что объект описывается именно одной гистограммой признаков? Так никто не делает. Обычно берут сразу некоторую совокупность таких гистограмм, иначе вектор признаков будет малоинформативным.
Что касается вашей картинки, то с чего вы взяли, что объект описывается именно одной гистограммой признаков? Так никто не делает. Обычно берут сразу некоторую совокупность таких гистограмм, иначе вектор признаков будет малоинформативным.
Рейтинг основных форумов
Городские форумы
Городской форум
Городской форум для новичков
Нижегородская политика
Жалобная книга
Бабский форум
Мужской
Анонимный медицинский форум
Дурацкие вопросы
Автофорумы
Автофорум главный
Девушка за рулем
ВАЗ форум
4х4 форум
Жалобный
Шевроле Форум
Такси
Автозапчасти
Гаражный форум
KIA-форум
Рено форум
Hyundai Форум
VAG Форум
Форумы покупок
Центр раздач: информационный форум
Глав-Пристрой (со всех форумов, взрослый)
Совместная покупка
Совместная покупка: центральный
Совместная покупка: взрослый
Совместная покупка: вкусный
Совместная покупка: мама и малыш
Совместная покупка: уютный
Совместная покупка: сбор предоплаты, раздачи
Совместная покупка: услуги
Совместная покупка: область
Совместная покупка: Дзержинск
Совместная покупка: Саров
Зарубежные интернет-покупки
Покупаем вместе
Покупаем Вместе: Основной
Покупаем вместе: БОЛЬШОЙ ШОПИНГ (взрослый)
Покупаем вместе: БЕБИ-ШОП (детский)
Покупаем вместе: ДОМОВОЙ
Покупаем вместе: ГАСТРОНОМ
Покупаем вместе: Сбор предоплаты, раздачи
Покупаем Вместе: пристрой
Покупаем Вместе: услуги
Выгодная покупка
Выгодная покупка - общие вопросы
Выгодная покупка - взрослый
Выгодная покупка - детский
Выгодная покупка - сбор предоплаты, раздачи
Выгодная покупка - объявления
Форум закупок
Мой малыш
Мой малыш - Основной
Мой малыш - Объявления. Общий
Мой малыш - Объявления: детская одежда
Мой малыш - Объявления: детская обувь
Мой малыш - Объявления: детский транспорт, игрушки, мебель
Халявный
Халявный (основной)
Котята и др. животные
Элитный (продажа неликвидных товаров)
Услуги
Домоводство
Полезный форум
Бытовые проблемы
Деревенский форум
Домоводство
Цветочный форум
Форум владельцев кошек
Дачный. Основной.
Бытовая Техника
Творческий
Рукоделие основной
Форумы по интересам
Фиолетовый форум
Сделаны в СССР
Музыкальный
Кино форум
Кладоискатели и коллекционеры
Рыболовный
Охотничий
Стильный форум
Флирт, Любовь, Знакомства
Фотофорум
Здоровье
Развитие Человека
Пивной форум
Кулинарный
Парфюмерный
Парфюмерная Лавка
Собачий форум
Собачий форум: Основной
Собачий форум: пристрой животных
Наши Дети
Наши дети
Школьный форум
Особые дети
Технофорумы
Интернет-НН
GPS форум
Мобильный форум
Техно-форум
Технотуса
Проф. и бизнес форумы
Бизнес форум
Фотография
Недвижимость
Банковский форум
Медицина
Форум трейдеров
Бухучет и аудит
Юридический
Подбор персонала
Разработчики ПО
Строительные форумы
Строительный форум (основной)
Окна
Форум электриков
Мебель
Кондиционирования и вентиляция
Форум строительных объявлений
Форум проектировщиков
Все строительные форумы
Туризм, отдых, экстрим
Туризм, отдых, экстрим
Спортивные форумы
Клуб болельщиков
Спортплощадка
Боевые искусства
Велофорумы Нижнего Новгорода
Велофорум Нижнего Новгорода
Путешествия
Нижегородская область
Недвижимость
Недвижимость
Ипотека
Земельный форум
ТСЖ
Садоводческое товарищество
Жилые районы
Автозаводский район
Сормовский район
Мещерское озеро
Все форумы районов
Форумы домов
Корабли
Новая Кузнечиха
Октава ЖК (ул. Глеба Успенского)
Мончегория ЖК
Аквамарин ЖК (Комсомольская пл.)
Сормовская Сторона ЖК
КМ Анкудиновский парк ЖК
Красная Поляна ЖК (Казанское шоссе)
Времена Года ЖК (Кстовский р-он)
Стрижи ЖК (Богородский р-он)
На Победной ЖК (Победная ул., у дома 18)
Окский берег ЖК (п. Новинки)
Цветы ЖК (ул. Академика Сахарова)
Деревня Крутая кп (Кстовский р-он)
Опалиха кп (Кстовский р-он)
Юг мкр. (Южный бульвар)
Гагаринские высоты мкр.
Бурнаковский мкр.
Белый город мкр. (60-лет Октября ул.)
Зенит ЖК (Гагарина пр.)
Седьмое небо ЖК
Все форумы домов
Частные форумы
Свадебный форум
Саровский Клуб Покупателей
Июньские мамочки
Форум безумных идей
Ночной форум
Королевство кривых зеркал
Ищу вторую половинку!
Лютики-цветочки КУПЛЯ-ПРОДАЖА
Отряд стройности
Пчеловодство
Форум ленивых
Волейбольный клуб туристов
Встречи для секса
Буду мамой!
Алкогольный форум
Лютики-цветочки
Котоводство
Форум сексуального опыта
Свободка
Форум модераторов
Форум забаненных
Новый форум модераторов
Отзывы и предложения (техподдержка)
Последние темы форумов
Форум
Тема (Автор)
Ответов
Программист-разработчик Full-Stack
ГК "Kolobox"
70000 -
100000 руб.
100000 руб.
Высшее образование, стаж работы более 5 лет, полная занятость
Разработчик .net
Profit Search
70000 -
100000 руб.
100000 руб.
Неполное среднее образование, стаж работы 3-5 лет, полная занятость
Карта сайта | 18+

ООО «Сеть городских порталов»
© 1999 - 2024
Реклама на NN.RU +7 (831) 261-37-60, reklama52@iportal.ru
Раздел технической поддержки | Для Роскомнадзора и госорганов: juristnn@iportal.ru
Реклама на NN.RU +7 (831) 261-37-60, reklama52@iportal.ru
Раздел технической поддержки | Для Роскомнадзора и госорганов: juristnn@iportal.ru




Т.к. вы неавторизованы на сайте. Войти.
Т.к. вы не трастовый пользователь. Как стать трастовым.
Т.к. тема является архивной.